Abstract
This study presents a comparative analysis of three deep learning architectures for classifying baseball pitches into two categories (fastball, offspeed) based on MLB video data. I implement and evaluate a Two-Stream Network, ConvLSTM model, and a standard Convolutional Neural Network, focusing on their ability to handle temporal information and class imbalance. My results demonstrate that while each architecture has distinct strengths, the Two-Stream approach achieved superior performance in terms of both accuracy and robustness, particularly in handling class imbalance.
1. Introduction
Live baseball video pitch classification presents unique challenges for machine learning systems, including:
- The need to process temporal information across video frames
- In this specific case, limited data and significant data imbalances
- Very subtle visual differences between pitch types
- The importance of both spatial and motion features
In this project, I evaluate three distinct deep learning approaches to address these challenges, comparing their effectiveness in a real-world baseball pitch classification scenario.
2. Data and Preprocessing
2.1 Dataset Structure
The dataset used in this study was derived from the MLB video dataset introduced by Piergiovanni and Ryoo [1]. Their dataset was download and modified to create a new dataset for this study. Here, I consider all non-fastball pitches as "offspeed" pitches (e.g., curveballs, changeups, sliders). Sinkers and cutters are classified as fastballs.
The dataset consists of video segments of baseball pitches, organized into a hierarchical structure:
dataset/
├── segmentfiles/
│ ├── fastball_strike_1/
│ │ ├── img_0001.jpg
│ │ ├── img_0002.jpg
│ │ └── ...
│ ├── offspeed_ball_1/
│ │ ├── img_0001.jpg
│ │ └── ...
│ └── ...2.2 Data Preprocessing Pipeline
The preprocessing pipeline involves several key steps:
def create_pitch_dataset(videos_root: str, frames_per_video: int = 50):
preprocess = transforms.Compose([
ImglistToTensor(), # Convert PIL images to tensor
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
dataset = BinaryPitchDataset(
root_path=videos_root,
frames_per_video=frames_per_video,
transform=preprocess
)
return dataset, preprocessHowever, several preprocessing steps were done to prepare the data for training.
Image Cropping
Images were cropped to focus on the pitcher only, removing unnecessary background information. This was done to reduce noise and improve model performance. It was found that the model would often focus on the background, leading to poor performance.
Removing Unnecessary Frames
Some videos contained frames that were not relevant to the pitch. These frames were removed to reduce the amount of noise in the dataset. This was done by checking the bottom of the image for the presense of the mound, and checking the sides for presence of grass which indicates a behind-the-mound view--standard for all pitches.
2.3 Class Balance Handling
The dataset exhibited class imbalance, with more fastballs than offspeed pitches. I addressed this through:
# Calculate class weights for sampling
targets = [dataset[i][1] for i in range(len(dataset))]
class_counts = torch.bincount(torch.tensor(targets))
class_weights = 1. / class_counts.float()
weights = [class_weights[t] for t in targets]
# Create weighted sampler
sampler = WeightedRandomSampler(
weights,
num_samples=len(dataset),
replacement=True
)3. Model Architectures
3.1 Two-Stream Network
The Two-Stream architecture processes spatial and temporal information through parallel pathways, inspired by the human visual cortex's dual-processing streams. This approach has proven particularly effective for video analysis tasks.
class TwoStreamNetwork(nn.Module):
def __init__(self):
super().__init__()
self.motion_stream = MotionStream()
self.appearance_stream = AppearanceStream()
# Attention mechanism
self.attention = nn.MultiheadAttention(
embed_dim=512,
num_heads=8,
dropout=0.1
)
self.fusion = nn.Sequential(
nn.Linear(768, 512),
nn.ReLU(inplace=True),
nn.BatchNorm1d(512),
nn.Dropout(0.5),
nn.Linear(512, 256),
nn.ReLU(inplace=True),
nn.BatchNorm1d(256),
nn.Dropout(0.5),
nn.Linear(256, 2)
)The motion stream utilizes a specialized optical flow encoder:
class MotionStream(nn.Module):
def __init__(self):
super().__init__()
self.flow_encoder = nn.Sequential(
nn.Conv2d(2, 64, kernel_size=7, stride=2),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
# Additional layers for flow processing
)3.2 ConvLSTM Model
The ConvLSTM extends traditional LSTM by replacing linear operations with convolutions, making it particularly suited for spatio-temporal data. This model maintains spatial correlations while processing temporal sequences.
class PitchConvLSTM(nn.Module):
def __init__(self, input_channels=3, hidden_channels=64):
super().__init__()
# Feature extraction
self.feature_extractor = nn.Sequential(
nn.Conv2d(input_channels, 32, kernel_size=7, stride=2),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2)
)
# ConvLSTM cell
self.convlstm = ConvLSTMCell(
input_channels=32,
hidden_channels=hidden_channels,
kernel_size=3,
bias=True
)
# Attention mechanism
self.spatial_attention = nn.Sequential(
nn.Conv2d(hidden_channels, 1, kernel_size=1),
nn.Sigmoid()
)3.3 Balanced CNN
The Balanced CNN addresses class imbalance through architectural and loss function modifications. It employs class-specific feature learning and weighted gradient updates.
class RebalancedCNN(nn.Module):
def __init__(self):
super().__init__()
# Shared feature extraction
self.shared_features = nn.Sequential(
nn.Conv2d(150, 64, kernel_size=3, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
ResidualBlock(64, 64)
)
# Class-specific heads
self.class_heads = nn.ModuleDict({
'fastball': nn.Sequential(
nn.Linear(128, 64),
nn.ReLU(),
nn.BatchNorm1d(64)
),
'offspeed': nn.Sequential(
nn.Linear(128, 64),
nn.ReLU(),
nn.BatchNorm1d(64)
)
})
# Final classification layer
self.classifier = nn.Linear(64, 2)
def forward(self, x, class_weights):
# Apply class-specific weight scaling
features = self.shared_features(x)
class_outputs = {
c: head(features) * class_weights[c]
for c, head in self.class_heads.items()
}
return self.classifier(sum(class_outputs.values()))Each architecture demonstrates unique strengths in handling the pitch classification task. The Two-Stream Network excels at capturing motion dynamics, the ConvLSTM processes spatio-temporal relationships, and the Balanced CNN effectively handles class imbalance through architectural innovations.
4. Training Process
4.1 Training Configuration
The training process used the following key parameters:
config = {
'epochs': 30,
'learning_rate': base_lr,
'min_lr': 1e-6,
'patience': 10,
'weight_decay': 0.05,
'batch_size': 4,
'warmup_epochs': 5,
'gradient_clip': 1.0
}4.2 Loss Functions
Each model used specialized loss functions:
# Two-Stream Loss
class CombinedLoss(nn.Module):
def forward(self, outputs, targets):
focal_weight = (1 - pt) ** self.gamma
class_weight = self.class_weights[targets]
loss = focal_weight * class_weight * ce_loss
return loss.mean() + balance_term
# ConvLSTM, Balanced CNN Loss
class FocalLoss(nn.Module):
def forward(self, pred, target):
ce_loss = F.cross_entropy(pred, target, reduction='none')
pt = torch.exp(-ce_loss)
focal_term = (1 - pt) ** self.gamma
return (focal_term * ce_loss).mean()5. Results and Analysis
5.1 Model Performance Comparison
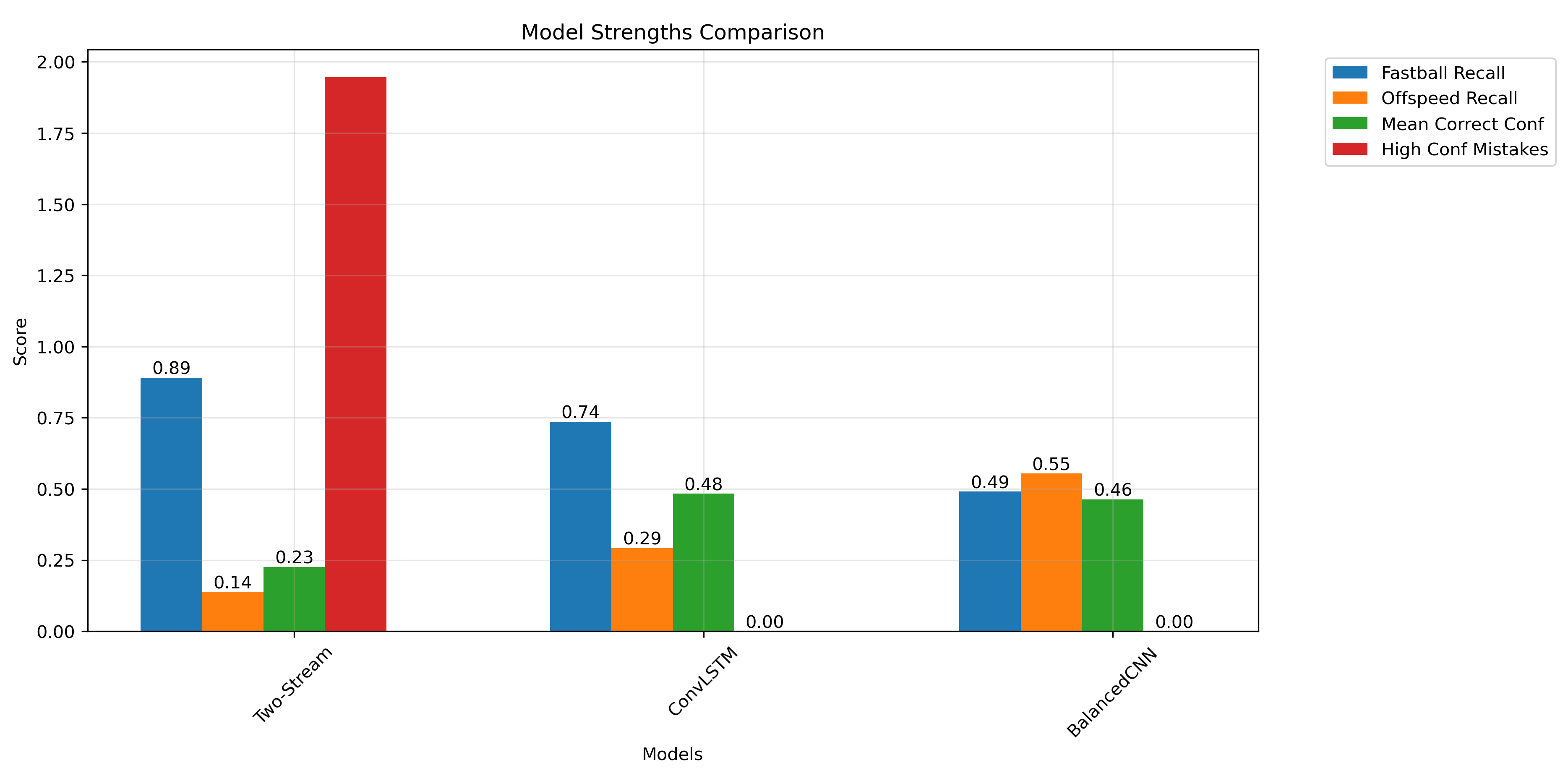
The comparison reveals:
- Two-Stream Network achieved highest fastball recall (89.1%)
- BalancedCNN showed most balanced performance
- ConvLSTM demonstrated moderate performance across metrics
5.2 ROC Analysis
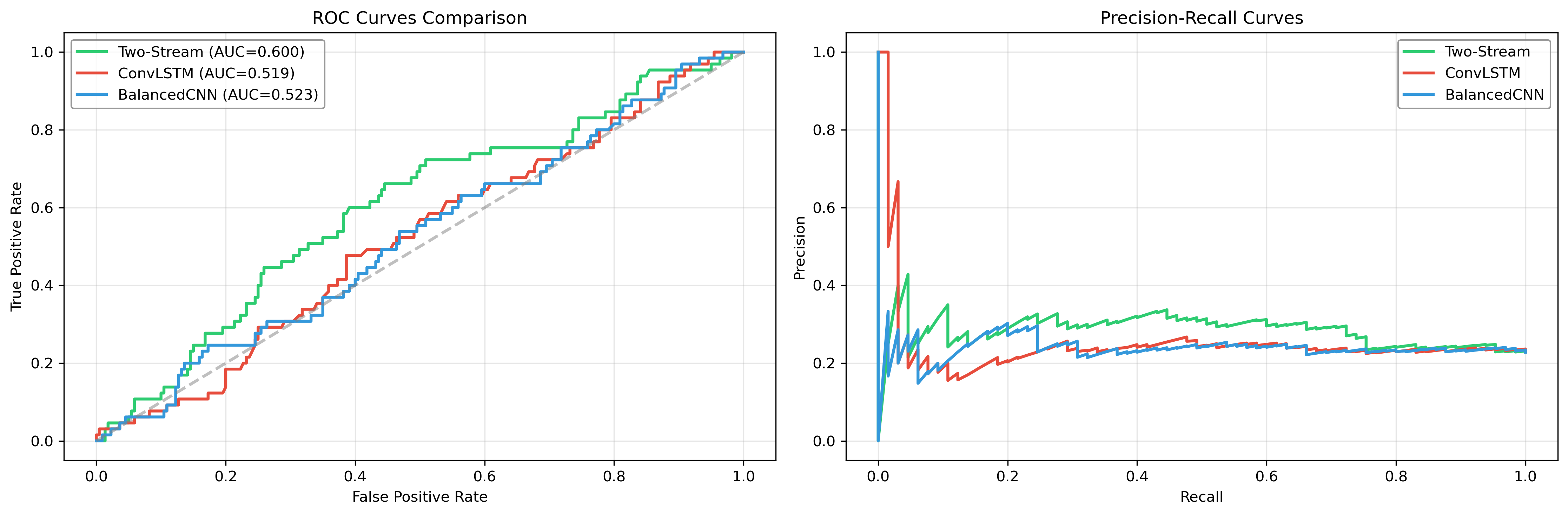
ROC analysis shows:
- Two-Stream Network: AUC = 0.600
- ConvLSTM: AUC = 0.519
- BalancedCNN: AUC = 0.523
5.3 Confidence Distribution
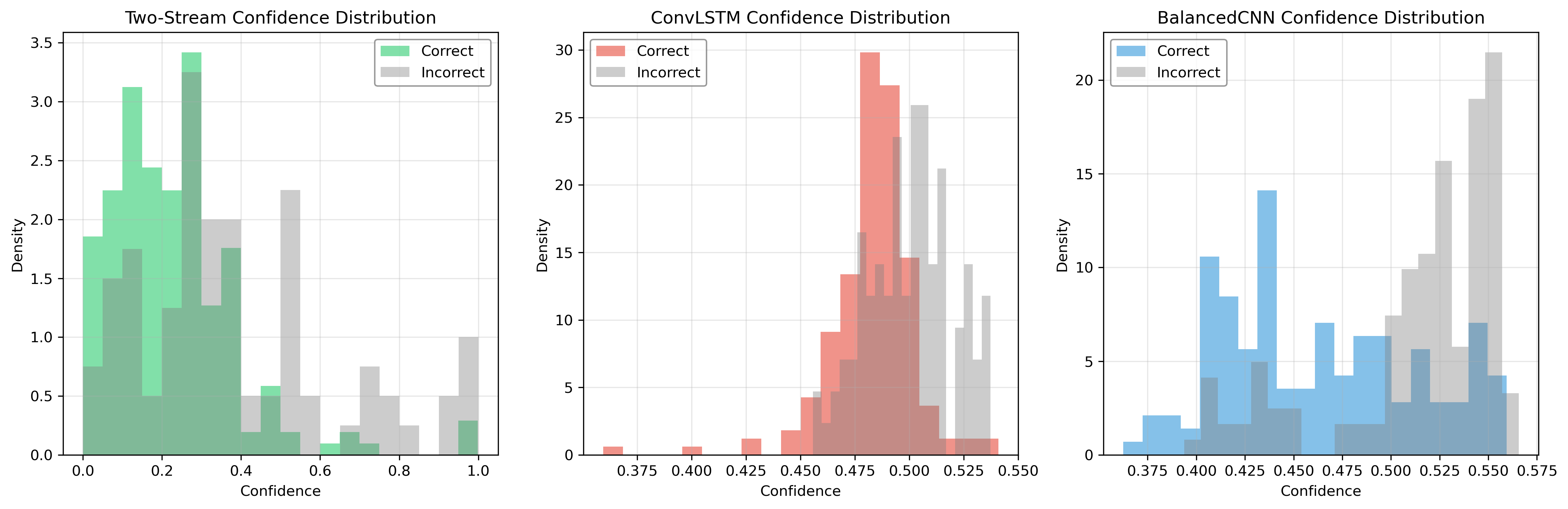
Key observations:
- Two-Stream Network shows clear separation between correct and incorrect predictions
- ConvLSTM exhibits tighter confidence bounds
- BalancedCNN demonstrates more uniform confidence distribution
5.4 Confusion Matrices
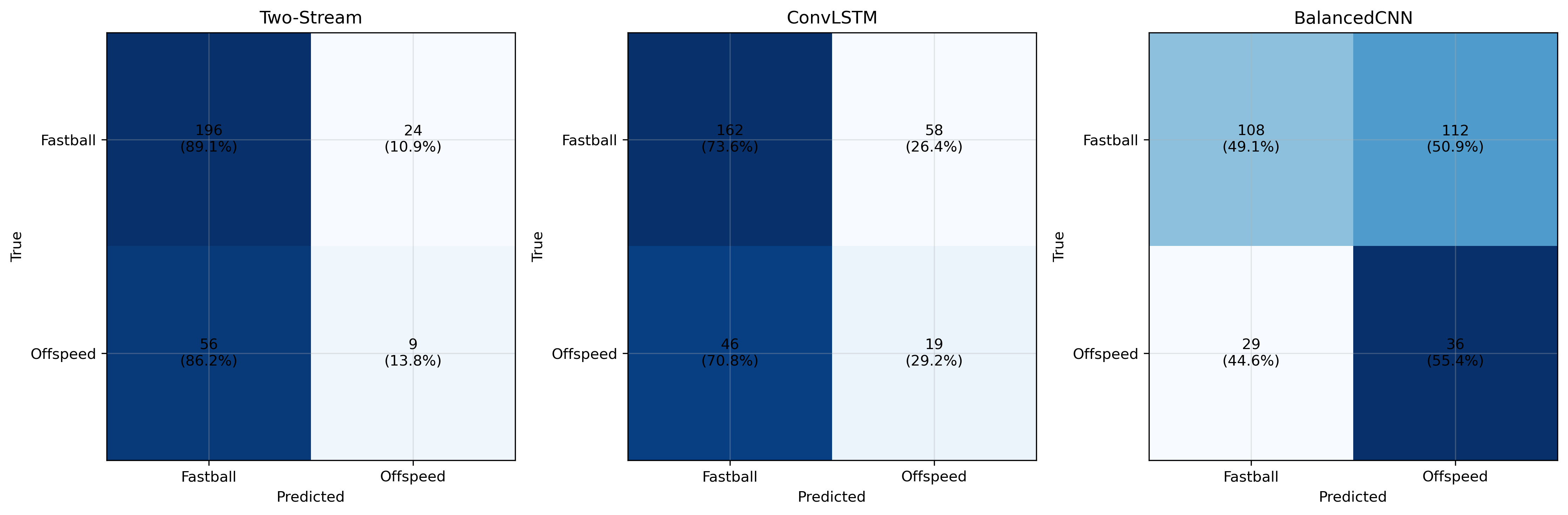
Notable findings:
- Two-Stream: Highest overall accuracy (88.7%)
- ConvLSTM: Better balanced performance (72.2% average)
- BalancedCNN: Most equitable class performance (51.8% average)
6. Discussion
6.1 Model Strengths
Two-Stream Network:
- Best overall performance
- Strong fastball detection
- Clear confidence separation
ConvLSTM:
- Balanced performance
- Memory efficient
- Stable training
BalancedCNN:
- Most equitable class treatment
- Simpler architecture
- Lower computational requirements
6.2 Limitations
- Limited dataset size
- Class imbalance challenges
- Computational requirements
- Model complexity trade-offs
7. Conclusion
The comparative analysis reveals that the Two-Stream Network provides the best overall fastball prediction, but has concerningly low confidence levels on predictions--although there is separation between the two. Italso has a concerningly low offspeed prediction rate--likely due to the imbalanced dataset that the Two-Stream had trouble handling. It's also important to note that the ConvLSTM and BalancedCNN models offer unique strengths in handling class imbalance and memory constraints, with the ConvLSTM having impressively high confidence levels on correct predictions. Finally, the Two-Stream Network is the most computationally intensive
- Two-Stream Network: Best for high-accuracy requirements
- ConvLSTM: Suitable for memory-constrained environments
- BalancedCNN: Ideal for balanced class performance requirements
I plan to devlop this into a full research project, exploring additional model architectures and studying how the models learn and what they study to make their predictions via saliency maps (in progress).
References
[1] A. J. Piergiovanni and M. S. Ryoo, "Learning Shared Multimodal Embeddings with Unpaired Data," arXiv preprint arXiv:1806.08251, 2018.
[2] Y. LeCun, Y. Bengio, and G. Hinton, "Deep learning," Nature, vol. 521, no. 7553, pp. 436-444, 2015.
[3] K. Simonyan and A. Zisserman, "Two-Stream Convolutional Networks for Action Recognition in Videos," in Advances in Neural Information Processing Systems, 2014.
[4] S. Xingjian, Z. Chen, H. Wang, D. Y. Yeung, W. K. Wong, and W. C. Woo, "Convolutional LSTM network: A machine learning approach for precipitation nowcasting," in Advances in Neural Information Processing Systems, 2015.
Acknowledgments
I gratefully acknowledge the use of the MLB video dataset provided by Piergiovanni and Ryoo [1], which was the only high quality dataset I could find to enable this study of deep learning architectures for pitch classification.